
Si bien son innegables las bondades del uso de un Query Caché en un motor de base de datos, debemos tener claros algunos conceptos y situaciones antes de decidir utilizarlo intensivamente.

Al publicarse el artículo “Memcached: un alivio para las bases de datos” he recibido algunas opiniones, Manuel Lagar, comenta:
Interesante artículo. Pero estas características ya deben ser implementadas nativamente por las bases de datos, me consta que Oracle y Sqlserver si lo hacen (se que son propietarias y caras), no se si mysql lo hace…
A quien le respondí:
“Hola Manuel, como bien apuntas, las bases de datos deberían implementar un “Query Cache” (me imagino que a esto te refieres), el tema es que no siempre es conveniente usarlo.
Un cacheo de los queres inyecta un overhead en el motor de las bases de datos, que muchas veces implica lockeos de tablas, y por ende ralentiza las IO (entradas/salidas). Cuando se manejan volúmenes de tráfico del orden de los millones, no es tan bueno tener este tipo de overhead.
Fíjate que los ejemplos de sitios que usan memcached son sitios que manejan tráfico por millones, rankeados en algunos casos Top 50, en algunos casos Top 10 en la escala mundial de manejo de tráfico.”
Es un buen pie como para hablar un poco más de los Query Cachés, y para hacerlo, voy a enfocarme en la implementación de MySQL. Como conclusión, intento fundamentar el por qué no es necesario usar Query Caché junto con Memcached Server, y por qué es contraproducente.
Funcionamiento
Arrancamos diciendo que el Query Caché es una característica de MySQL a partir de la versión 4.0, y que representó en su momento una mejora rotunda de la velocidad de respuesta del motor, muchas veces superando en 5 veces la ejecución de un simple SELECT en un MySQL3 comparado con un MySQL4.
En algunas instalaciones, el query caché de MySQL viene desactivado por default. Podemos chequearlo en nuestro motor haciendo:
mysql>show variables like '%query%';
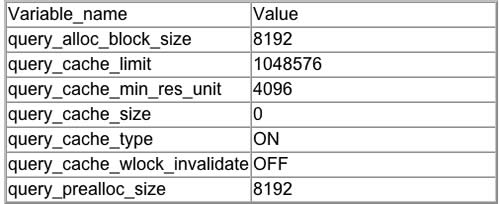
De todas estas variables, las que nos definen si esta activo o no son “query_cache_type” y “query_cache_size“.
query_cache_type
- Determina si el query caché esta activo y el tipo de cacheo.
- 0: Cache inactivo.
- 1: Siempre se cachea, salvo que lo pidamos explicitamente con SQL_NO_CACHE.
- 2: Solo se cachea con la opción SQL_CACHE.
query_cache_size
- Indica el tamaño del set de datos cacheados. Si se establece en 0, se inhabilita el caché, independientemente de query_cache_type.
Ventajas y desventajas
La principal ventaja del cacheo de queries frente al esquema contrario, radica en el beneficio que implica el ahorro del tiempo de parseo frente a cada comando SELECT. El query ya no debe parsearse ni calcular su plan de ejecución, sino que ahora solo nos enfocamos a capturar el resultado cacheado.
A su vez, el cacheo de queries funciona para sentencias SELECT únicamente. Es decir, que no le sacamos el jugo con subselects, partes de UNION, stored procedures, comandos SHOW, etc. Ahora bien, como en todo esquema computacional, rige el principio de costo-beneficio.
El cacheo de queries no es gratis. El hecho de almacenar el resultado de un SELECT le agrega un overhead al ciclo normal de ejecución. Por ejemplo:
mysql>SELECT field1, field2 FROM table1 WHERE field1='value1';
El motor realiza el parseo, calcula los indices a utilizar, captura los resultados y “cachea los resultados”. Luego, si el cliente realiza el mismo query:
mysql>SELECT field1, field2 FROM table1 WHERE field1='value1';
El motor solo se remite a capturar el resultado del caché. Pero bueno, aquí viene la parte triste de la historia. MySQL tiene una política de invalidación de datos de cache muy “agresiva”.
Ante cualquier acción de escritura sobre una tabla, invalida todos los datos cacheados en la misma, independientemente de los datos escritos…Veamos un ejemplo de este concepto. Arrancamos con el caché vació:
mysql>SELECT field1, field2 FROM table1 WHERE field1='value1';
Resultset1 calculado y cacheado.
mysql>SELECT field1, field2 FROM table1 WHERE field1='Pichongol';
Resultset1entregado desde el caché.
mysql>INSERT INTO table1 (field1, field2) VALUES('1','Daniel Lopez');
Registro insertado y VACIADO DE TODOS LOS DATOS CACHEADOS PARA table1.
mysql>SELECT field1, field2 FROM table1 WHERE field1='value1';
Resultset1 calculado y cacheado.
Queda demostrado entonces la falta de “inteligencia” del motor para darse cuenta que el INSERT no afecta el resultado de “SELECT field1, field2 FROM table1 WHERE field1=’Pichongol“, y por lo tanto no debería ser invalidado.
De todas formas, no es una crítica sino una observación. El hecho de dotar de esta lógica al Query Cache quizás lo dejaría muy complejo, y la performance se vería mas afectada de lo necesario.
Sistemas intensivos en lecturas vs. Sistemas intensivos en escrituras
Entonces, teniendo en cuenta esta invalidación agresiva de resultados cacheados ante una acción de escritura, queda preguntarnos: cuándo realmente nos conviene utilizar el Query Cache, y bajo qué circunstancias. Para responder esta pregunta, lo primero que deberíamos revisar es el sistema en cuestión.
Si nuestro sistema es intensivo en reads (lecturas), entonces el beneficio que podríamos sacar de un Query Caché, es claro. Los datos del caché se invalidarían muy esporádicamente, para luego volver a capturarse desde este último.
Si nuestro sistema es intensivo en writes (escrituras), seguramente deberíamos pensar en desactivarlo: ante un flujo de INSERTS o UPDATES los datos seria invalidados constantemente, y los SELECT no solo sufrirían el overhead de almacenar el query en el caché, sino que no lo estarían utilizando ante dichas invalidaciones.
Query Cache + Memcached Servers
Es frecuente en sistemas web de tráfico masivo, y a veces no tan masivo, encontrar esquemas que utilicen algún medio para persistir datos en disco (base de datos) + algún medio de acceso rápido a esos datos (Memcached Server por ejemplo).
Me ha tocado por razones laborales, ponerme a evaluar que tan necesario es el Query Caché cuando lo combinamos con el uso de caché en memoria. La realidad es que con dichos esquemas de acceso rápido a los datos residentes en memoria, se disminuyen drásticamente los reads en la base de datos, llegando en la mayoría de los casos al orden del 90% de queries que ya no se efectúan.
De esta manera, nuestro sistema web termina convirtiéndose en un sistema crítico en writes (viéndolo desde el lado de la base de datos), y por tal motivo, se convierte en un sistema que constantemente invalida los datos del Query Caché.
Conclusión rápida y furiosa: Es contraproducente el uso de Memory Cache + Query Caché.
En su análisis sobre Sistemas intensivos en lecturas vs. Sistemas intensivos en escrituras, pasa por alto un detalle de gran importancia. Las páginas web (que es lo que nos ocupa), son sistemas en los que se acometen muchas lecturas y pocas escrituras por lo que en el 99% de los casos el uso del query cache será beneficioso. Además siempre se pueden utilizar tablas auxiliares para cierto tipo de operaciones de escritura masiva (contadores,estadísticas,sesiones, etc) y utilizar las extensiones de MySQL INSERT DELAYED y INSERT DELAYED … ON DUPLICATE UPDATE para acometer las actualizaciones en estas tablas sin influir en el tiempo de ejecución del script.
Sobre el uso de Memcached, también se pasa por alto un detalle importante, Memcached puede hacer persistir objetos en memoria para distintas máquinas a lo largo de una red y de esta forma varias máquinas se aprovechan del calculo realizado por una. Si hablamos de instalaciones de un solo servidor, el coste de las funciones serialize y unserialize reducen bastante las ventajas de utilizar Memcached.
Por mi experiencia, Memcached es especialmente productivo para entornos de balanceo de carga y funciona especialmente bien en combinación con Lighttpd+FastCGI.
Borja, te respondo:
“En su análisis sobre Sistemas intensivos en lecturas vs. Sistemas intensivos en escrituras, pasa por alto un detalle de gran importancia. Las páginas web (que es lo que nos ocupa), son sistemas en los que se acometen muchas lecturas y pocas escrituras por lo que en el 99% de los casos el uso del query cache será beneficioso”
Bueno, este punto me interesaba que quede bien claro, pero parece que fracase en el intento ;).
Siempre hablando en sistemas web, el hecho de usar por ejemplo Memcached convierte a la aplicacion claramente en un sistema intensivo en escrituras (Memcached reduce los reads a la db en el orden del 90% en promedio). En esas condiciones, la invalidacion del query cache es constante.
“Además siempre se pueden utilizar tablas auxiliares para cierto tipo de operaciones de escritura masiva (contadores,estadísticas,sesiones, etc) y utilizar las extensiones de MySQL INSERT DELAYED y INSERT DELAYED … ON DUPLICATE UPDATE para acometer las actualizaciones en estas tablas sin influir en el tiempo de ejecución del script.”
100% de acuerdo. La criticidad en la que se enfoca el articulo se basa en los reads, no en los writes.
“Sobre el uso de Memcached, también se pasa por alto un detalle importante, Memcached puede hacer persistir objetos en memoria para distintas máquinas a lo largo de una red y de esta forma varias máquinas se aprovechan del calculo realizado por una.”
No entiendo a que apunta esta apreciacion. De hecho, el query cache tambien puede ser “leido” por varios servidores.
Creo que a lo que refieres es a la distribucion del query cache.
El query cache pertenece solo a un motor de base de datos, y no puede ser compartido por otro motor. Si tengo 4 database servers, entonces tendre 4 query caches.
Sin embargo, en el caso de los memcached servers, puedo tener un pool de ellos, que logicamente es visto como un unico gran cache, y puede ser compartido por varios web servers. Creo que a eso apuntaba esta apreciacion.
“Si hablamos de instalaciones de un solo servidor, el coste de las funciones serialize y unserialize reducen bastante las ventajas de utilizar Memcached.”
Yo creo que depende de lo que cacheas. Si cacheas objetos con una estructura determinada, el coste de serialize – unserialize no es tan grande como traerse n queries de la database y armar el objeto en ese momento. Depende de lo que cacheas.
“Por mi experiencia, Memcached es especialmente productivo para entornos de balanceo de carga y funciona especialmente bien en combinación con Lighttpd+FastCGI.”
Buen dato, yo aun no lo he probado con Lighttpd, aunque no creo que falte mucho 😉
Saludos y me paso por tu blog
[…] viene desactivado por default. Podemos chequearlo en nuestro motor haciendo: Articulo completo: http://www.maestrosdelweb.com/editorial/dilemas-sobre-query-cache/ […]
puntual
hola, soy estudiante y quisiera preguntarle sobre las query caches que utiliza Mysql en cuanto a su algoritmo de reemplazo,¿que algoritmo utiliza y si se le puede implementar en todo caso el que se vea conveniente?
muchas gracias